TensorRT の EntropyCalibrator の観察
https://abemii.github.io/posts/quantization_calibration/ から移行。
ディープニューラルネットワーク (DNN) の量子化は、 主に、モデルの Weight と Activation を単精度浮動小数点 (FP32) から 8ビット整数 (INT8) へ 変換することを指す。 この変換は、浮動小数点のスケール $s$ と整数のゼロ点 $z$ を用いて表される。
本稿では、このスケール $s$ の決定のためのキャリブレーションの手法の一つ、 Entropy についてそのアルゴリズムと振る舞いについて書く。
なお、量子化そのものについては、文献 [1] で Quantization Aware Training (QAT) や 8 ビット以下の量子化などを含めた俯瞰的なサーベイが行われている。 また、文献 [2] では、各キャリブレーション手法の評価を含む、実践的な内容が述べられている。
Calibration のアルゴリズム
代表的な Calibration のアルゴリズムとして、以下の 3 種類が挙げられる。[2]
- Max: Calibration において観測された最大の絶対値を使う。
- Entropy: もとの浮動小数点の値と量子化フォーマットで表現できる値の間の情報損失を最小化するために KL-divergence を使う。
- Percentile: Calibration において観測された値の絶対値の分布のパーセンタイルを使う。 例えば、 99% の場合は残りの 1% をクリップする。
なかでも、TensorRT においてデフォルトの手法となっている Entropy についてその振る舞いを理解したい。
Entropy
GTC2017 での NVIDIA による発表資料 [3] をもとに、どのように閾値(スケール)が決定されるかを観察する。
FP32 から INT8 への変換を、再エンコーディングと捉え、その間の情報の損失を最小化することを考える。 2 つのエンコーディングを確率分布と見れば、その2つの確率分布の距離は Kullback-Leibler divergence を用いて表せる。 KL-divergence により、与えられたエンコーディングを近似したときの、情報損失の量を測ることができる。 したがって、情報損失が最小となるような近似を作るのが目的となる。
アルゴリズム
- 入力:アクチベーションのヒストグラム $$ H = [m_0, \ldots, m_{N-1}], N = 2048 $$ を作成する。
- ここから、参照分布 $P$ (
FP32の分布)を生成し、 これとの KL-divergence が最小となるような候補分布 $Q$ (INT8の分布) を見つけることが目的となる。 そのため、以下の操作を $i=2^8, \ldots, N$ に渡って繰り返し、 $P, Q$ 間の KL-divergence を計算する。
まず、参照分布 $P$ を作る。
- $H$ の $i-1$ 番目までのビンを使い、 $$P = [m_0, \ldots, m_{i-1}]$$ とする。
- $H$ の $i$ 以降のビンの合計を計算し、これを外れ値 $O$ とする。 $$O = \sum_{k=i}^{N-1} m_k$$
- 外れ値 $O$ を $P'$ の末尾に足したものを参照分布 $P$ とする。 $$ P(i-1) \leftarrow P(i-1) + O $$
- 次に、候補分布 $Q$ を作る。
- $P, Q$ それぞれをその合計で割り、確率分布とする。 $$ P \leftarrow P / \sum{P} $$ $$ Q \leftarrow Q / \sum{Q} $$
- 得られた参照分布 $P$ と候補分布 $Q$ について、KL-divergence を計算する。 $$ KL(P||Q) = \sum_{k=0}^{i-1} P(k) \log\frac{P(k)}{Q(k)} $$
以上から、 $KL(P||Q)$ が最小となる $i$ を求める。
- 最終的な閾値 $\theta$ は、 以下のように求まる。 $$ \theta = (i + 0.5) W $$ ここで、 $W$ はビンの幅。
TensorRT の EntropyCalibrator での振る舞いの観察
公式の実装を参考に、 実際にどのように上記のループが行われるのか観察してみる。
実験設定
FP32からINT2への量子化を想定し、上のループを実行してみる。- キャリブレーションに用いる
FP32のアクチベーションは、 $\chi^2$ 分布から生成した $2^8$ 個のランダムな値を用いる。 - 入力のヒストグラム $H$ として、上記を $2^4$ 個のビンに分割したものを用いる(下図)。

結果
下図に、$i = 2^2, \ldots, 2^4$ について、参照分布 $P$ (青)と候補分布 $Q$ (橙)をプロットした。
- 初期は、外れ値 $O$ が大きいため、参照分布 $P$ の末尾の頻度が大きく、 その結果、候補分布 $Q$ との KL-divergence が大きい値となっている。
- $i$ が増加するにつれ、 KL-divergence が小さくなっていく様子が見られるが、 $i=15$ で $\infty$ となっているのが気になる。 KL-divergence の定義から、 KL-divergence が $\infty$ になる場合はあるので、 実運用上問題がないかは検証する必要がありそう。

まとめ
本稿では、 TensorRT での EntropyCalibrator の中身の挙動について アルゴリズムを振り返り、簡単な例での中身の挙動を観察した。
Reference
- [1] Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer. A Survey of Quantization Methods for Efficient Neural Network Inference. arXiv preprint arXiv:2103.13630, 2021.
- [2] Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius. Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation. arXiv preprint arXiv:2004.09602, 2020.
- [3] Szymon Migacz. Nvidia 8-bit inference width tensorrt. In GPU Technology Conference, 2017. https://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
- [4] Awesome Model Quantization
- 最新の量子化関連の論文のまとめ
fern.vim でファイルを削除できない問題の解決
https://abemii.github.io/posts/fern-trash/ から移行。
fern.vim
fern.vim は Vim のファイルエクスプローラプラグインの一つである。 以前までは NerdTree を使用していたが、最近 fern.vim に移行してみた。 キーマップを NerdTree に合わせることができることもあり、使い勝手が良い。
ファイルを削除できない
しかし使う中で、ファイルを消すことができないという問題に気づいた。
ファイルを消すキーマップは、デフォルトでは、 Shift-D となっている。
Shift-D を打鍵すると、ウインドウ下部に以下のメッセージが表示され、
y で削除できるはずだった。
The following 1 files will be trashed /path/to/file Are you sure to continue (Y[es]/no):
しかし、何も起きない。
:h fern
困ったときは help に頼るべきだ。
help によれば、 fern でファイルを削除する方法は 2 つある。
- fern-action-trash: ファイルを「ゴミ箱」に移す。
- fern-action-remove: ファイルを消去する(rm と同じ)。
Shift-D は前者を実行するが、そのためには、 以下のように CLI のゴミ箱コマンドが必要であるらしい。
*<Plug>(fern-action-trash=)*
Open a prompt to ask if fern can send the cursor node or marked nodes
to the system trash-bin. It uses the following implementations to send
the node(s) into system trash-bin.
OS Requirement~
macOS: osascript (OS builtin)
Windows: PowerShell (OS builtin)
Linux: trash-cli or gomi (Users need to install)
https://github.com/andreafrancia/trash-cli
https://github.com/b4b4r07/gomi
Ubuntu では、通常どおり apt-get install で trash-cli をインストールすることができる。
apt-get update apt-get install trash-cli
結果
trash-cli がインストールされた状態で Neovim を起動し直すと、 確かにファイルを削除できるようになった。
1 items are trashed
まとめ
困ったらまず help を見よう。
論文読み Training data-efficient image transformers & distillation through attention
https://abemii.github.io/posts/reading-deit/ から移行。
DeiT 論文を読んだのでそのメモ。
多くの ViT 研究において、 DeiT の学習スキームがフォローされている。 最近読んだ ShiftViT1 において言及されており、ちゃんと読んでおこうと思っていた。
書誌情報
@misc{touvron2021training, title={Training data-efficient image transformers & distillation through attention}, author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou}, year={2021}, eprint={2012.12877}, archivePrefix={arXiv}, primaryClass={cs.CV} }
- 図表は特に言及のない限り本論文からの引用。
概要
- ViT と同じネットワーク構造のモデルを用い、学習方法を工夫することで精度を上げ、 また、学習に必要な計算リソース・時間を大きく短縮した。
- 蒸留トークン (distillation token) を用いた蒸留手法を提案。 class token とは別の token を用いて 教師モデルからの教師信号を学習させることで、より性能を高められる。
- 学習時の工夫について詳細な分析を行い、よくまとめている。
Distillation
Distillation (蒸留) の方法は、 Soft と Hard に大別される。
- Soft なほうは、生徒モデルの logits $ Z_s $ と 教師モデルの logits $ Z_t $ を KL-loss を使って最小化する。
- Hard なほうでは、 教師モデルの hard decision $ y_t = \mathrm{argmax}_c Z_t(c) $ を使い、 Cross entropy で最適化する。
- この方法は Soft と異なりパラメータフリーであるという良さがある。
- さらに実験では label smoothing と呼ばれる手法を取り入れている。 すなわち、 真なクラスを $ 1 - \epsilon $ とし、その他のクラスを $\epsilon$ で等分するといった方法である。
蒸留トークン (distillation token)
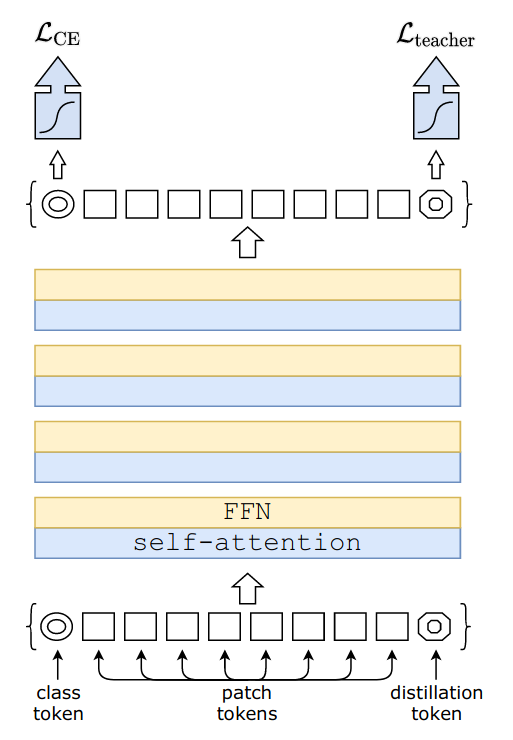
実験結果より、 - 蒸留トークンを使わない場合、3 種類の蒸留手法 (行わない/ソフト/ハード) のうち ハードが最も良かった。 - 蒸留トークンを使用し、 ハード蒸留を使って学習を行った後、 クラス予測には、クラス embedding, 蒸留 embedding, 両方の3種類の方法を使うことが考えられる。 このうち最も結果がよかったのは、 蒸留 embedding を使うもので、 これは、教師モデルである convnet の帰納バイアスの恩恵を受けているからだろうと著者は考えている。
学習戦略に関する ablation study
重みの初期化
Transformer は比較的初期化方法に敏感であり、方法によっては収束しない場合がある。 最終的に切断正規分布 (truncated normal distribution) を使用して重みの初期化を行った。
data augmentation
- Transformer では convolution に比べより多くのデータ量が必要。
- convolution はより多くの事前分布を統合することができる。
- 同じ大きさのデータセットで学習を行うためには、大規模な data augmentation を 行う必要がある。
- データ効率の良い学習を行うために、異なるタイプの強力な data augmentation を評価。
- Auto-augment, rand-augment, random erasing により性能が向上。
- ほとんどの data augm. 手法は有用であることが分かった。
正則化と最適化
- 最適化アルゴリズム
- ViT と同じく AdamW を用い、学習率を同じ値を用いることが最も良い結果となった。
- ただし、 Weight Decay の値は、収束のためにより小さい値を用いることとした。
- Stochastic depth
- Dropout は ノードをオフにする = 横方向にネットワークを小さくする。
- Stochastic depth は Layer 数を変化させる = 縦方向にネットワークを小さくする。
- Short なネットワークを学習し、 Deep なネットワークを得ることができる。
- 特に深い transformer の収束を促進させる。
- 正則化
- Mixup
- Cutmix
- repeated augmentation
- 一つの画像からいくつかの augmentation 画像をつくることで、 1 バッチ内で同じサンプルを複数回読み込ませる手法。
- 提案した学習スキームの鍵となる構成要素。
Exponential Moving Average (EMA)
- EMA を行うことで、0.1 pt 程度性能が向上したが、 fine tuning すると、同じ結果となった。
異なる解像度での fine tuning
- 学習は解像度は 224 で行ったが、 fine-tuning は 384 で行った。
- Fixing the train-test resolution discrepancy
- 学習時の解像度は、テスト時より小さい解像度のほうが良いという先行研究。
- FixefficientNet と異なり、学習時の augmentation は弱めずに行う。
- Positional embeddings の補間
学習時間
- batch norm を使っていないので、 batch size を減らしても性能に影響しない。 よって、大きなモデルを学習するのが簡単になる。
参照
- https://zenn.dev/takoroy/scraps/ced7059a36d846
- takoroy さんによる本論文のメモ。
- https://qiita.com/supersaiakujin/items/eb0553a1ef1d46bd03fa
- stochastic depth について、 supersaiakujin さんによる記事。
feline.nvim: is the order a cool and fast status bar?
https://abemii.github.io/posts/feline.nvim/ から移行。
序
私の Neovim は起動時間が長い。 180 ms もかかっていた。 1 秒もかかっていないので、気にするほどのことでもないのかもしれないが、 生の Neovim が 5ms 程度で起動することを考えると、速さを追い求めたくなってしまう。 速さにこそ本質がある。
起動・動作の高速化のためにいくつかのことを行ってみたが、 ここではステータスバーを vim-airline から feline.nvim に変更してみた。
もともと airline はなんかかっこいいという程度の理由で使っており、 大した設定もしていなかった。よく意味もわからず表示していたものもあり、今回はこれを見直すことにした。
feline.nvim は lua で書かれたプラグインで、 vimscript で書かれたものよりも高速に動作することが期待できる。 lua で書かれたステータスバープラグインは他にもあるが、 なんとなく feline.nvim を使うことにした。
結果として、 Neovim の起動時間が半分程度になり( 118ms 程度 → 64ms 程度)、 なかなか良い見た目のステータスバーとなった。
本稿では、 vim-airline と feline.nvim の起動時間の比較と、私の設定を紹介する。
環境
PC
- OS: Ubuntu 20.04.3 LTS
- CPU: Intel(R) Core(TM) i7-9700K CPU @ 3.60GHz
- RAM: DIMM DDR4 Synchronous 2133 MHz x2 (32GB)
Neovim
- NVIM v0.6.1
- feline.nvim v0.4.3
feline.nvim の導入
README に書かれている通りにインストールする。 私の場合は、 vim-plug を使用しているので、以下のようにインストールした。
Plug 'feline-nvim/feline.nvim'
ステータスバーに表示されている内容は以下の通りである:
- Vim mode (NORMAL とか INSERT とか)
- File type (python とか cpp とか)
- File name
- Git branch, add, change, remove
- Diagnostics
- File OS
- Cursor position and percentage in file
feline.nvim の設定
プラグインの設定は lua で記述する必要がある。 README のリンクにあったこの例を参考に設定を記述した。
しかし、この例では Diagnostics の情報を builtin lsp からとるようになっており、私が使用している coc.nvim には対応していない。 そのため、 coc.nvim の Diagnostics の情報をとってくる部分は自分で書く必要があった。1 実装をみる限りでは、builtin lsp の各 severity の個数をとってきて表示しているようなので、 これを coc.nvim から取得できるように実装すれば良い。
実装すべきなのは以下の 2 つ:
- 各 severity の個数の表示
- (info, warning, error, hint) について、その個数を表示する。
- 表示が必要かどうかの判定
- もし、 diagnostics の情報がとれない、あるいは、個数が 0 であれば何も表示しない。
coc.nvim の diagnostics の情報は、辞書型の変数 b:coc_diagnostic_info に格納されている。
よって、この変数を lua で読み取るような関数を実装する。
-- ある severity の diagnostics が存在するかを判定 local function diagnostics_exist(severity) local info = vim.b.coc_diagnostic_info if (not info) then return false else local count = info[severity] if count > 0 then return true else return false end end end -- ある severity の diagnostics の個数を返す local lsp_get_diag = function(str) local info = vim.b.coc_diagnostic_info if (not info) then return '' else local count = info[str] if (not count) then return ' 0 ' else return ' '..count..' ' end end end
以上の設定はここにある。
起動時間の比較
ここでは vim-airline と feline.nvim を読み込んだときの起動時間を比較する。
使用した init.vim は次の通り。
- vim-airline
filetype off call plug#begin('/tmp/nvim/plugged_airline') Plug 'vim-airline/vim-airline' call plug#end() set termguicolors filetype plugin indent on
- feline.nvim
filetype off call plug#begin('/tmp/nvim/plugged_feline') Plug 'feline-nvim/feline.nvim' call plug#end() set termguicolors lua << EOF require('feline').setup() EOF filetype plugin indent on
それぞれ :PlugInstall を行った後、 10 回ずつ起動して startuptime を記録し、その起動時間の平均をとった。
# log startuptime
$ repeat 10 nvim -u init_feline.vim --startuptime /tmp/startuptime_feline.log
$ repeat 10 nvim -u init_airline.vim --startuptime /tmp/startuptime_airline.log
# calculate average
$ cat /tmp/startuptime_airline.log | grep "NVIM STARTED" | awk '{m+=$1} END{print m/NR;}'
57.5417
$ cat /tmp/startuptime_feline.log | grep "NVIM STARTED" | awk '{m+=$1} END{print m/NR;}'
19.2784
確かに、 feline.nvim のほうがだいぶ起動時間が短いことがわかる。
結
本稿では、 vim-airline から feline.nvim に変更してみた結果を紹介した。 また、 feline.nvim で coc.nvim の diagnostics 情報を読み取る方法も書いた。
参考
Is the order a partial formatter for python?
Python コードはブラックであるべきだ、そうコーヒーのように。 しかしときたま、ある人が不可解な理由でミルクを入れるように言ってくることがある。 カフェラテは飲めないから、結局妥協してカフェマキアートに落ち着くのだ。
(black-macchiato README より引用、邦訳。)
Black is awesome
Python のフォーマッタとしては、以下の3つのツールが人気らしい。 *1
なかでも black は特に最近人気があるらしく、自分も使わせてもらっている。
black の良い点として、カスタマイズ性が低さが挙げられる。 これにより、誰が使用しても標準的と考えられるスタイルに修正することができるため、 プロジェクト内でスタイルを統一するのも容易であろう。
しかし、その思想の強さゆえか、ファイルの一部のみの修正は許されていない。 他の(自分の変更箇所ではない)部分は変更したくないなどの理由により、 ファイルの一部(例えば選択範囲)のみをフォーマットしたいといった要望は 自分のみならず多くあると思われるが、それは叶わないようである。
本稿では、(冒涜的かもしれないが)これを叶えるツール black-macchiato の Neovim への導入方法と使い方について書く。
black-macchiato の導入 (Neovim)
black-macchiato は Vim 用のプラグインが公開されているため、それを使うのが良いと思われる。 *2
インストール
まず、 black-macchiato 本体を Neovim 用の仮想環境にインストールする。
source activate neovim # virtual env for neovim pip install black-macchiato
Neovim とのインテグレーションには、上述の通り、 vim-black-macchiato を用いる。 基本的には README 通りにインストールすれば問題ない。 自分は vim-plug を使っているため、次のようにインストールした。
Plug 'smbl64/vim-black-macchiato'
設定
こちらも、ほとんど README 通りに設定した。
let g:black_macchiato_path = fnamemodify( g:python3_host_prog, ':h') . '/black-macchiato' autocmd FileType python xmap <silent> <buffer> <Leader>f <plug>(BlackMacchiatoSelection) autocmd FileType python nmap <silent> <buffer> <Leader>f <plug>(BlackMacchiatoCurrentLine)
このとき以下の2点について注意した。 - black-macchiato の実行ファイルのパスを指定する - coc.nvim のマップと競合しないようにする
まず、 black-macchiato の実行ファイルのパスの指定については、 上記の仮想環境に black-macchiato がインストールされているとすると、
<virtual env>/bin/ |-- python |-- black-macchiato |-- ...
のように配置されているはずなので、 g:python3_host_prog 変数から、
そのディレクトリ (<virtual env>/bin/) を取得することで、ハードコードを避けられる。
次に、 coc.nvim のマッピングとの競合についてだが、 自分は coc.nvim のフォーマットに関するマップを次のように設定している。
" Formatting selected code. xmap <leader>f <Plug>(coc-format-selected) nmap <leader>f <Plug>(coc-format-selected) xmap <leader>F <Plug>(coc-format) nmap <leader>F <Plug>(coc-format)
先程の black-macchiato に関するマッピングは、この記述の後に置かないと coc-format-selected のマップにより上書きされてしまう(逆に言えば、 coc-format-selected についてのマップを black-macchiato で上書きできれば良い)。 一つのファイルに設定を書いている場合は単に後に書けば良いだけだが、 複数のファイルに分けて設定を記述している場合は読み込み順について注意が必要だと思われる。
また、読み込み順について、プラグインの読み込みが上記設定の読み込みよりも後になることがあり、
設定が上書きされてしまうことがあるようである。(実際、私の環境では後になっていた)。
そこで、次のようにプラグインの記述を変更してしまうのもありかもしれない。
*3
本変更は、本家にマージされたので、必要ない。
--- a/plugin/black-macchiato.vim +++ b/plugin/black-macchiato.vim @@ -1,7 +1,5 @@ -let g:black_macchiato_path = "black-macchiato" - function s:RunBlackMacchiato() range - let cmd = g:black_macchiato_path + let cmd = get(g:, 'black_macchiato_path', 'black-macchiato') if !executable(cmd) echohl ErrorMsg echom "black-macchiato not found!"
動作確認
Is the order a well-managed CocInstall?
導入
coc.nvim の拡張を管理する方法について。
自分は、Neovim の設定をすべて dotfiles レポジトリで管理している。 そのため、新しく環境構築をする必要がある場合、
./setup.sh
を実行するだけですべてがインストールされる。
coc の拡張についても setup.sh 中に
nvim +'CocInstall coc-xxx coc-yyy' +qa
などと書いていた。 (通常の拡張のインストール方法と同じように)
これはこれで良いのだが、 Neovim 関連の設定が .config/nvim/ の外に出てしまっているのが気持ち悪いし、
ここに追加したとしても、このスクリプトを実行するのは最初の一度きりなので、使い勝手が悪かった。
(そして何よりも、ここに追加するのを忘れることが多かった)
この拡張のリストをどこかで管理しておいて、 Neovim を起動する度にインストールされているかチェックし、 もしインストールされていなければ自動的にインストールしてほしい。
解決方法
これは init.vim に以下のように記述することで解決可能である。*1
let g:coc_global_extensions = [ \'coc-xxx', \'coc-yyy', \]
Neovim の起動時にこの設定が読み込まれ、もしインストールされていなければ自動的にインストールしてくれる。 嬉しいね。